Introduction
CS50의 첫주차가 시작되었다. 모두를 위한 컴퓨터 과학 (CS50 2019)의 첫번째 챕터는 컴퓨팅 사고이다.
강의를 보셨다면 알겠지만 데이비드 말린(David Malan)교수님께서 굉장히 굉장히 열정적으로 가르치신다.
내용도 재밌고 짧은 시간으로 구성되어 있어서 집중이 잘 되는 것 같다. (부스트코스기준) 영어가 편하신분들은 원본 수업영상으로 보시는 게 나을 수 있습니다. CS50 chap.1 youtube
2진법 (Binary system)
“What is Computer Science?” => 문제를 해결하는 과정이라는 말로 포문을 여셨다.
문제를 해결하는데 앞서 기계들을 사용할 때 입력과 출력에 대해 어떻게 표현할지 정하는 컴퓨터과학의 첫번째 개념은 바로 정보자체의 표현방법이다.
사람들은 0~10까지라는 숫자를 이용해 수를 표현하는데 반해 컴퓨터는 0과 1로 밖에 받아들이지 못한다.
이는 binary system(2진법)이라고도 불리는데 이 0과 1를 가지고 컴퓨터는 숫자뿐만아니라 글자,사진,영상,소리등 많은 것을 저장할 수 있다.
우리는 123이라는 것을 보았을때 자동적으로 (100x 1) + (10 x 2) + (1 x 3)계산하여 단순한 숫자 1,2,3의 나열이 아닌 123(백이십삼)으로 인식한다. 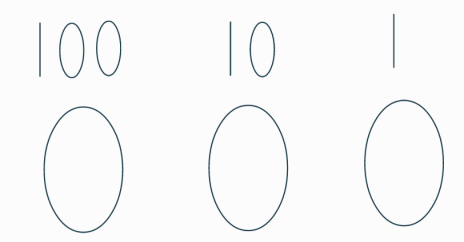
123(백이십삼) 이라면 위의 사진의 100의 자리에 1, 10의 자리에는 2, 1의 자리에는 3이 들어갈 것이다. 9에서 10을 넘어갈때 재밌는 현상이 나타나는데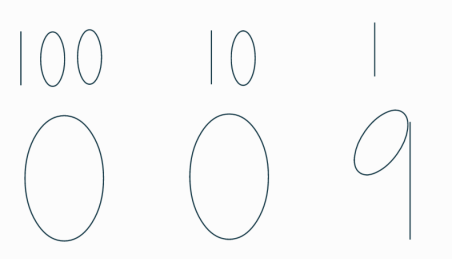
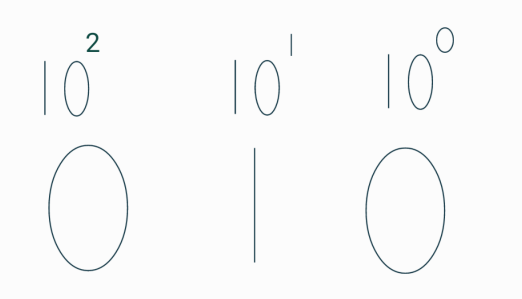
우리가이렇게 당연하게 여기는 체계는 어떤 숫자든 같은 방법으로 나타낼 수 있고 이 방법을 바탕으로 2진법에도 적용할 수 있다.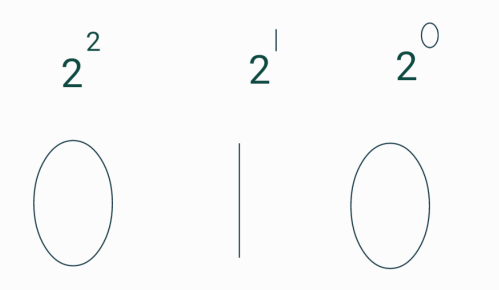
우리가 보기에는 010으로 10진법 기준이라면 010(십)으로 볼 수 있으나 2진법을 기준으로 본다면 21 x 1이기 때문에 2라는 숫자를 010으로 표현하는 것이다. (10진법은 9를 넘으면 자리가 바뀌어 표시했던 것처럼 2진법은 0~1범위로 1을 넘은 숫자를 표기할 수 없다.)
이렇게 컴퓨터는 2진수로 숫자를 나타낼 수 있는데 숫자는 2,4등 이런작은 숫자들만 있는게 아닌 큰 숫자들을 표현하기 위해 더 많은 0과 1이 필요하다 (EX. 215 x 1를 표현하면 1000000000000000와 같이 많은 0과 1이 필요)
우리는 이를 비트라고 부른다. 비트는 단지 binary의 0과1을 의미한다고 보면된다.
자, 이제 2진법이라는 건 알았는데 이게왜 컴퓨터와 연관이 있는가 ?
컴퓨터는 기본적으로 전기를 가지고 구동되는 기계이다. 유일한 자원이 전기인 것이다.
이 전기를 가지고 Trun on { 0 } / Trun off { 1 }로 나타내어 2진법을 표현할 수 있는 것이다. 이것을 바탕으로 수많은 비트를 가지고 정보를 표현하는 것이다. 비트가 늘어남에따라 많은 비트를 부르는 용어가 각각 생겼는데 Byte의 경우 8bit를 의미한다. 8자리의 [xxxxxxx] x에 각각 0과 1이 표시될 수 있는데 각 x는 전기를 사용해 Off/On로 0과 1를 표현한다. 각 bit의 on/off를 표현할 수 있는 아주 작은 전기 스위치를 트랜지스터라고 하는데 오늘날 컴퓨터는 수백만,수십억개의 트랜스터를 가지고 있다. 이들을 물리적으로 이용해서 정보를 표현하고 값을 저장하는 것이다. Ex.) 50이라는 숫자가 있다면 00110010으로 표현하고 1이 들어가있는 자리에 트랜지스터 각각에 아주 조금의 전기를 저장해서 숫자 50을 나타내는 것이다.
boostcourse에서 제공하는 자료
정보의 표현
지금까지 어떻게 숫자를 표현할 수 있는 지에 대해 알아봤다. 그러나 우리가 살고 있는 세계는 숫자로만 정보를 전달 할 수 없다. 그렇다면 메일, 문자들 같은 글자들은 어떻게 보낼 수 있는가 ? Trun on과 Trun off로 작동하는 트랜지스터를 활용해 어떻게 On,Off로 나타낼 수 있는가 ?
우리가 서로간의 약속을 하면 될 것이다. 1은 A를 2는 B를 의미한다고 ! 물론 실제로 1이 A를 의미하지는 않는다. 실제 A를 의미하는 것은 65이다. 문자나 메일같은 걸로 A라는 글자를 수신받았다면 우리는 0과 1의 패턴으로 표현된 65란 숫자를 받는 것이다. 이렇게 문자를 숫자로 표현할 수 있도록 정해진 표준이 있는데 그 중 하나가 ASCII(아스키코드/American Standard Code for Information Interchange)이다.
기본 ASCII코드는 총 128(27)개의 부호로 정의되어 있고 알파벳은 아래와같이 약속되어 있다.

위의 표를 보면 의문이 들지 모른다. 알파벳은 소,대문자 통틀어 52개밖에 없는데 나머지76개는 뭐지? 라고 말이다. 알파벳을 채우고 남은 나머지공간에는 ! ? ,등과 같은 기호를 표현하는 문자로 채워져있다.
기본 ASCII코드에서 나아간 것이 확장 ASCII코드인데 총 256(28)개를 표현 할 수 있다.
강의에서 나온 예제를 봐보도록하자72 73 33라는 숫자를 받았다면 이것이 의미하는 것은 HI!이다.
그렇다면 83 85 80 80 80 80 80 80 80 46 71 73 84 72 85 66 46 73 79 는 무엇을 의미할까 ?
바로 이 블로그의 주소인 suppppppp.github.io이다.
이런 ASCII는 미국편향적,영어편향적이다. 다른언어들도 많고 이모티콘도 많기 때문이다. 이모티콘 같은 것들은 사진같지만 키보드를 통해 입력한다. 실제로 알파벳으로 이루어진 기호에 불과하다. 이모티콘을 나타내는 0과1의 패턴도 있다.
그것이 바로 유니코드(Unicode)로 ASCII의 상위집합과 같다. 확장 ASCII는 당시 8비트(28=256)만 사용했고 이는 문자들을 사용하기에 충분하지 않았다. 유니코드는 8,16,24 혹은 32비트까지도 사용하므로 훨씬더 많은 0과1의 패턴을 표현할 수 있고 이모티콘도 가능하다.

이 기쁨 눈물 이모지를 표현하는 숫자는 128,514 이다 (십진수로) 이진수로 표현하면 11111011000000010
(참고로 ASCII의 128개의 문자와 유니코드의 초기 128개는 동일하므로 서로 호환가능하다.)
모바일을 예로 들면 우리가 누군가에게 기쁨 눈물 이모지를 보내면 숫자로 표현되는 코드를 보내는거고 그럼 그것을 전달받은 안드로이드나 ios가 기쁨 눈물 이모지로 표현하는 것이다.
물론 이모티콘 자체는 이미지이고 컴퓨터에서의 이미지는 수많은 작은 점들로 구성되어 있다. 저 기쁨 눈물 이모지 또한 각각의 점들로 이루어진 이미지인 것이다.
이미지를 구성하는 각각의 점들은 RGB체계에 의해 표현된다. (Red, Green, Blue) 옛날 사람들은 색깔을 나타기위해 0과 1만 사용하면 된다는 데 모두 동의했고 어떤 숫자가 어떤 색깔을 나타낼지를 정했다. 이를 위해서 색 체계가 필요하고 우리가 사용하는 RGB체계가 나온것이다. 왜 RGB체계를 택했나를 이야기해보자면 무지개는 색들을 모두 포함하고 있는데 이 무지개에 있는 색들은 Red, Green, Blue 3가지 색조합만으로 이루어졌다는 게 밝혀졌고 이 3가지를 잘 조합하면 무지개 내의 모든 색들을 표현할 수 있었기 때문이다. 그래서 이 각 3가지 RGB의 숫자들이 얼만큼 각 색을 사용하여 화면상에 점을 표현할 것인지 알려주게된다.
포토샵등의 프로그램들은 72 73 33 이런 패턴을 숫자로 해석해서 HI!로 표현하는대신에 RGB값으로 받아들인다. 72만큼의 R 73만큼의 G 33만큼의 B 를 섞으면 아래와 같은 색이나오고

이 색이 바로 기쁨 눈물 이미지의 얼굴색이다.

인터넷의 동영상이나 gif 같이 움직이는 것처럼 보이는 것들은 단순히 여러장의 사진들이다. 한 이미지뒤에 다음 이미지를 빠르게 나타내서 움직이는 것처럼 보이는 것이다. 바로 위의 기쁨 눈물 이모지 또한 여러장의 사진을 붙여 만든 gif에 불과하고 사진이 넘어가는 간격사이를 더욱 많은 사진들로 채워주고 사진->사진 넘어가는 속도를 조절해주면 동영상으로 변하게 되는것이다.
이것들이 오늘날 컴퓨터가 정보를 표현하는 거의 모든 방법이다 0과 1을 사용해서 2진수를 나타내고 이를통해 10진수를 사용하여 화면상의 글자나 색깔을 나타내고 더 나아가 영상까지 만드는 것
아날로그(Analog) to 디지털(Digital) 변환
강의에서 소리같은 아날로그(Analog) 신호를 디지털(Digital)로 변환하는 방법에 대해서 자세히 나오지는 않았지만 개인적으로 찾아보았다.
아날로그 => 디지털 변환은 총 3가지 단계로 이루어진다.
- 1단계 표본화 : 구간별 컷팅 (sampling)
Continuous 한 연속 신호를 discrete (이산적인) 신호인 불연속 신호로 변환한다.
자연적으로 발생하는 소리는 기계처럼 배! 고! 파! 끊겨서 소리가 들리지않는다.
소리가 배고파~이렇게 들리는데 신호적측면에서 보면 연속적인 신호라고 본다.
이 신호를 x축에 수직으로 잘라준다. 아래그림에서는 주황색선으로 표현했고
원래는 저것들 보다 훨~~씬 잘게 잘라준다. 편의상 몇 개만 그렸다.
이렇게 연속적인 신호를 이산적인 신호로 잘라주는게 샘플링(sampling)이라고 한다.
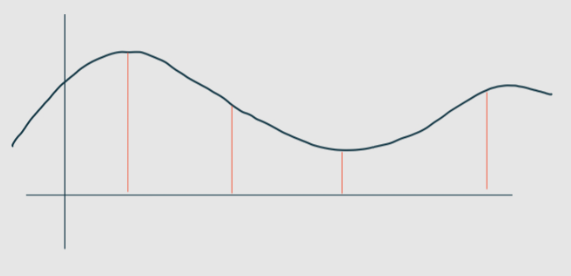
- 2단계 양자화 : 구간별로 자른 소리의 크기를 표현할 수 있는 근사값으로 변환한다.
이제는 소리의 크기를 측정할 차례다. 구간별로 자른 부분은 소리의 크기를 가지게 되는데
이때 7.9, 4.3, 2.1의 크기는 8, 4, 2 같은 근사값으로 보내준다.
이 근사값들의 범위가 1이 아닌 0.5, 0.1 단위로 세세한 소리의 크기를 저장 할 수 있다면
이게 바로 음질이 좋아지는 것이라고 볼 수 있다.
(근사값을 더 작데 보내고 + 구간을 더 잘게 쪼개면 음질이 좋아진다.)
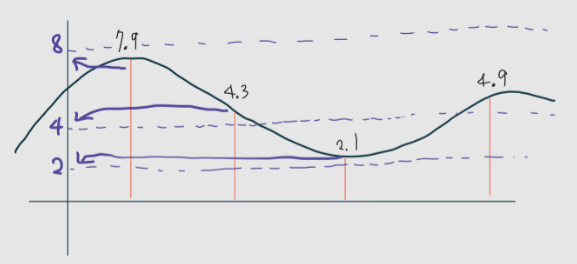
- 3단계 부호화 : 위에서 만들어준 근사값 8, 4, 2를 1000, 0100, 0010의 2진법으로 바꾸는 양자화 과정을 거쳐
아날로그 신호를 코드(2진법)인 디지털신호로 변환하여 컴퓨터에 입력된다.
아 모든 것들에서 결국 말하고자 하는것은 어떤 방법을 사용해서 정보를 나타내든 결국 0과 1로 표현된다.
boostcourse에서 제공하는 자료
알고리즘
이제 입력을 나타내는 방법에 대해 얘기했으니 출력에 대해 이야기해보자
어떻게 입력으로부터 출력을 얻을 수 있을까?  이 부분이 컴퓨터과학 중 알고리즘 사용되는 곳이다
이 부분이 컴퓨터과학 중 알고리즘 사용되는 곳이다
What is 알고리즘 ?
우리는 요즘 매체등을 통해 알고리즘이란 단어를 주위에서 많이 본다.
알고리즘이란, 문제해결 관점에서 바라본다면 알고리즘은 그저 문제를 해결하는 단계적 방법일 뿐이다.
원하는 문제를 풀기위해서는 어떤알고리즘을 사용해야할까 ?
오래된 문제인 전화번호부 책 문제로 예를 들어보자.
나는 전화번호부를 사용해봤던 세대라 어떻게 전화번호부책이 이루어져있는지 알지만 모르시는 분들이 있을 수 있으니 설명해보자면 우리나라 기준으로 ㄱ부터 ㅎ까지 이름(상호명이던 개인이던)순으로 번호가 적혀져있다.
이 강의에서는 미국의 예제니까 당연히 A-Z의 순서일것이다. 요즘 핸드폰에 있는 전화번호부기능과 이와 마찬가지이다. 연락처에 들어가면 이름의 순서대로 연락처가 있으니 말이다. 전화번호부 책과 핸드폰 연락처 기능이 같은 구성으로 이루어져있다는 걸 알았으니 그럼 우리가 누군가의 연락처를 찾을때 어떤 방법을 사용해서 찾을 수 있을까?
강의에서 나오는 예처럼 Mike Smith라는 이름을 찾는다고 가정해보자 ( 처음에 강의를 볼 때 한국식으로 생각해서 당연히 M부터 찾는 것이라고 생각했는데 강의를 듣다보면 S를 찾는 내용으로 설명한다. 그래서 미국이니까 성이 Smith이고 S부터 찾는다고 이해했다. 만약 S부터 찾지않아도 M을 찾는것으로 대입해서 이해해도 방법론적 내용이므로 무리는 없을 것이다.)
첫번째 방법으로 아주 심플하게 첫번째장부터 찾는 Mike Smith란 이름이 있는지 찾아나가는 방법이 있다.
한 장씩, 한 장씩 펼쳐가며 S페이지에 도착할 것이다. 이런것이 알고리즘이다. 문제 해결을 위한 Step by Step process ! 알고리즘이라는 것은 무엇인지 알았고 이 알고리즘은 올바른가?라고 묻는다면 올바르긴하나 매우 느리고 안좋은 방법이라고 말할 수 있을 것이다. Mike Smith를 찾는데 수백장을 넘겨야할지도 모르기 때문에 첫번째 장부터 찾아나가는 것은 너무나 비효율적이기 때문이다.
그럼 두번째 방법으로 책을 넘기는 장수를 2배로 늘린다면?? ex) 2,4,6,8,10 알고리즘은 올바른가?라고 질문하면 당연히 아니다 속도는 2배 빨라질지 모르나 홀수번째 페이지에 Mike Smith가 있다면 제대로된 검색이 이루어지지 않을것이다. 물론 약간만 수정하면 찾기도 가능하다 A~RSTU~Z 가 알파벳순서니까 T로 넘어갔다면 뒤로 1,2페이지 옮겨서 찾는 방법으로 할 수도 있다. 그러나 이 역시 책 페이지가 1,000장이 넘는 것처럼 찾아야할 페이지가 큰 수로 있는 경우 여전히 몇 백번을 실행해야한다. 첫번째 방법보다는 2배빨라졌으나 여전히 느린것이다.
그럼 어떻게 하는게 좋은방법일까? 실제로 우리가 전화번호부책이나 원하는 내용을 찾는 방법을 떠올려보자.(책 목차가 기재되어 있지않은 경우를 바탕으로 이야기한다.) 먼저 우리가 찾고자 하는 내용을 정하고 일단 책을 펼쳐볼 것이다. 그런 다음 펼친 책의 내용과 우리가 찾고자 하는 내용의 선후관계를 따져 찾고자 하는 내용이 펼친 페이지의 앞에 있을경우 앞부분을 찾을것이고, 찾고자 하는 내용이 펼친 페이지의 뒤에 있을경우 뒷부분을 찾을것이다.
이를 적용한 세번째 방법으로 Mike Smith의 예제또한 효율적으로 찾을 수 있다. 만약 책의 총 페이지가 1,024라면 중간인 512페이지를 펼쳐 512의 알파벳을 확인하고 해당 페이지 알파벳과 S의 위치를 비교하여 움직일 방향을 정할 수 있을 것이다. 1,024 512 2561286432168421 이렇게 10단계안에 우리가 원하는 페이지를 찾을 수 있다.
반면 첫번째 방법은 몇 단계나 거칠까? S의 위치에따라 다르겠으나 A-Z순서중 후반부에 있으므로 적어도 6,700번이상은 진행할 것이다. 최악의경우 1,024에 가까운 페이지를 봐야될 수 있다.(T부터 시작하는 사람,상호명이 없을 경우) 두번째 방법은 첫번째 방법보다 반정도 횟수를 줄일 수 있으나 최소 400번이상은 봐야한다.
이렇듯 알고리즘은 우리가 기본적으로 생각할 수 있는 직관이나 생각들을 어떤 문제해결을 위해 기계나 다른사람들이 이해할 수 있는 방식으로 표현하는 것이다. 그럼 알고리즘은 무엇인지 이제 이해가 되었는데..
어떤 알고리즘이 더 좋은 알고리즘인지는 어떻게 알 수 있을까 ? 아래의 그림을 봐보자

( X축 : 문제의 크기 , Y축 : 문제해결에 걸린시간 )를 각각나타낸다. 우리가 했던 전화번호부 책 문제를 대입해보면
X축은 전화번호부페이지의 수가 많아질수록 오른쪽으로
Y축은 페이지를 넘기는 시간(횟수)이 길어질수록 위로 올라가는 것이다.
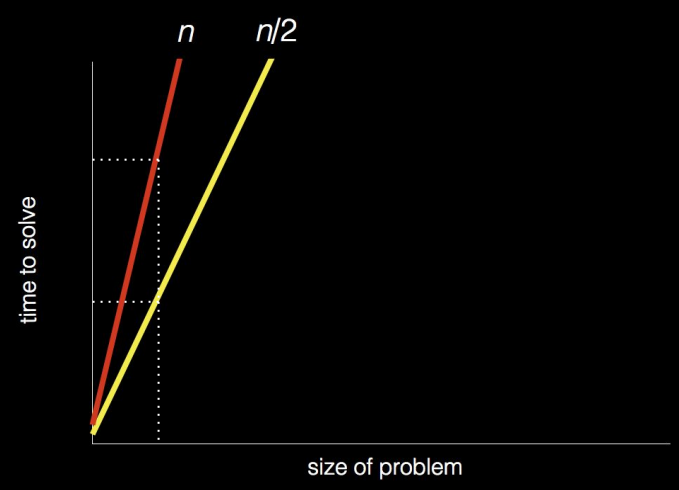
빨간색으로 표시된 선은 첫번째 알고리즘을 표현한 것이며 전화번화부 페이지 수 탐색과 소요시간(횟수) 사이의 비를 1:1관계로 보여준다. 기울기는 1인 직선으로 그려진다. 노란색으로 표시된 선은 두번째 알고리즘을 표현한 것이고 첫번째 알고리즘보다 2배 빠르게 탐색하므로 소요시간은 1/2일 것이고 기울기가 1/2인 직선으로 그려진다. 이걸 보면 같은페이지라도 두번째 방법(노란선)이 첫번째 방법(빨간선)에 비해 2배 빠르다는 것을 알 수 있다.
그렇다면 세번째 알고리즘은 어떨까 ? 세번째 방법의 경우 \(\log n\)의 그래프가 그려지는데 (\(\log\)함수는 잘 몰라도 상관없다.) 세번째 알고리즘의 진행방법을 보면
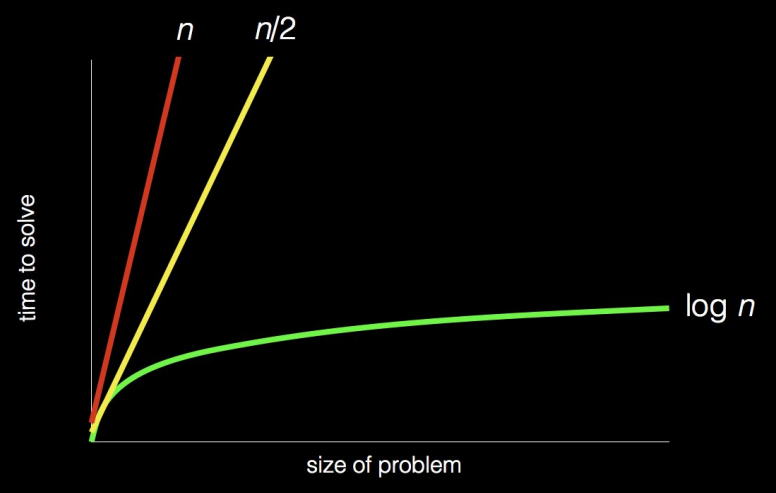
절반절반절반으로 진행했기때문에 페이지 수가 아무리 커져도 해결시간에 거의 영향을 주지않는다는 것을 \(\log n\)의 그래프를 보면 알 수 있다.예를들어 1,024의 페이지가 16배로 늘어난다고 가정해보자 (계산과정 단순화를 위해 2의 배수로 진행했다.) 1024 x 16 = 16,384 이다. 1,024보다 무려 15,360페이지나 많아졌기때문에 첫번째,두번째방법은 오랜시간이 소요하겠으나 세번째 방법의경우 16,3848,1924,0962,0481,024512 2561286432168421 총 14번이 소요되었다. 1,024 가 10번이 걸린것을 본다면 페이지가 15,360페이지나 증가했음에도 고작 4번의 횟수만 증가한 것이다.
Pseudo code
이것은 효율성 측면에서 아주 중요한 차이이다. 그럼 이 중요한 직관(생각)을 코드로 나타내 볼 것인데 이를 의사코드 (Pesudo code)라고한다. 정확한 정의는 없지만 영어던 어떤 언어든 우리의 생각을 간결하게 정리한 코드와 비슷한 구문을 말한다. Mike Smith를 찾는 알고리즘을 영어 의사코드로 나타낸 사진이다 (강의에서 진행한 사진)
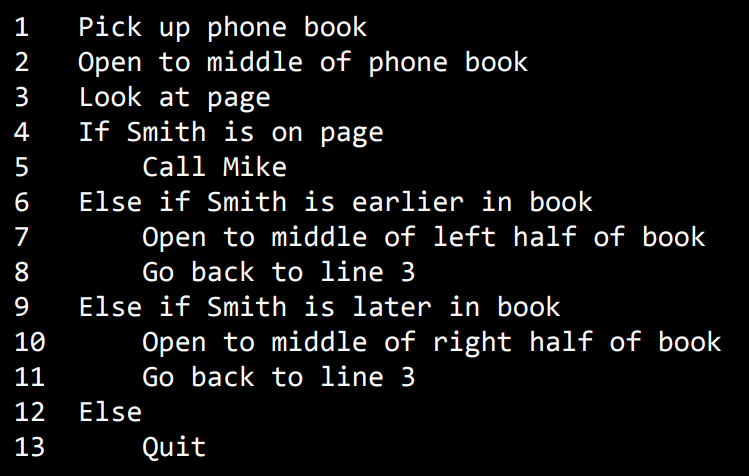
단계별로 무엇을 했는지 적고있다. (너무 자세히 적을 필요는 없다. 무엇을 하냐정도만 적는게 중요 ) 일종의 종속관계가 있다는 걸 확실히 하기위해 들여쓰기로 표시한것들이 있는데 예를 들어 Smith가 페이지에 있다는 Line 4가 참(True, 진실)일때만 Line 5로 넘어간다. 당연히 Line 4가 참이 아니면 ( Smith가 페이지에 없다면) 펼친 책의 왼쪽에 있을지 오른쪽에 있을지를 체크하는 것을 Line 6, 9에서 체크하고 계속 진행해나가야된다. 이걸 어떻게 반복할 수 있을지가 중요한 것인데 Go back to line을 사용해 왼쪽,오른쪽여부를 찾고 Line 3으로 가서 이것을 다시 반복하도록 만들었다. 물론 책에 우리가 찾는 Mike smith씨가 없을 수도 있다. 이렇듯 Line 4,6,9 조건에 해당하지않을경우 (Mike Smith가 없을경우) 탐색을 그만둘 수 있도록 만족하는 조건이 없을 경우(Line 12) 탐색을 그만둬라(Line 13)라고도 만들어줬다. 이 예시는 의사코드를 영여구문으로 작성하는 한가지 방법이었다.
이 의사코드에서 볼 수 있는 몇가지 특징들은 다음주 공부하게될 C나 요즘 자주쓰는 파이썬같은 언어에서도 볼 수 있는데 절차적 프로그래밍(procedural programming)이라고 모든 언어들에 공통적으로 존재하는 특징이다.
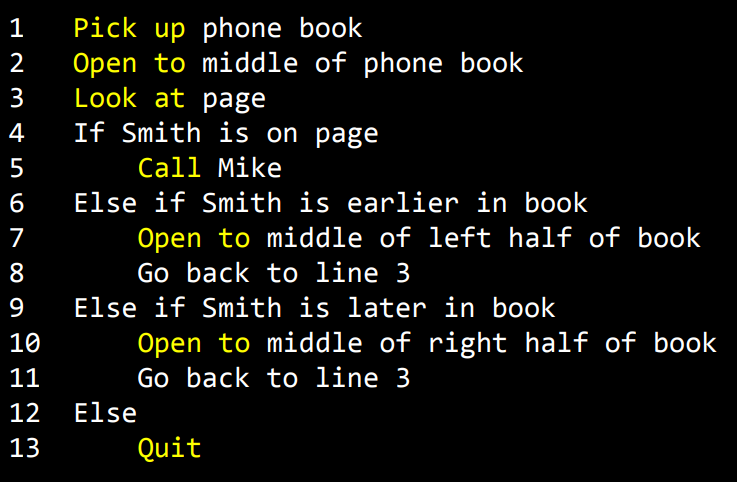
위 사진에서 노란색으로 강조된 부분들을 함수(function)이라고 한다.
함수는 컴퓨터에게 (이 경우는 사람에게) 무엇을 해야할지 알려주는 역할을 한다.
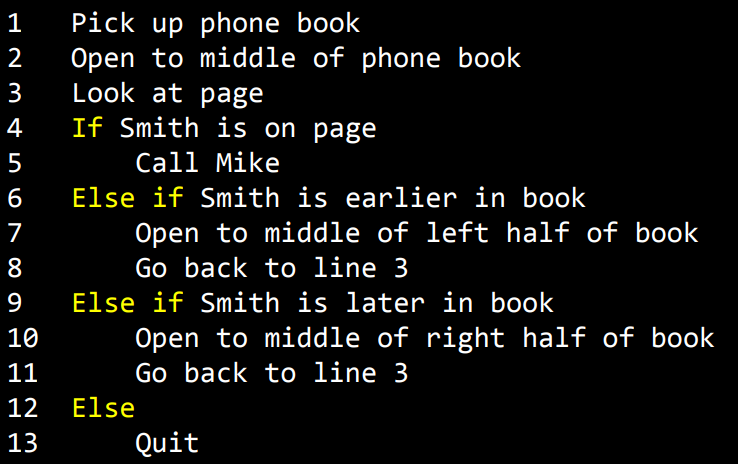
위 사진에서 노란색으로 강조된 부분들은 조건(condition)이라고한다.
여러 선택지중 특정 하나를 위해 설정하는 역할을 한다. 하나를 선택하는 결정을 내리기위해서는 조건의 내용이 필요한데 아래와 같이 설정한다.
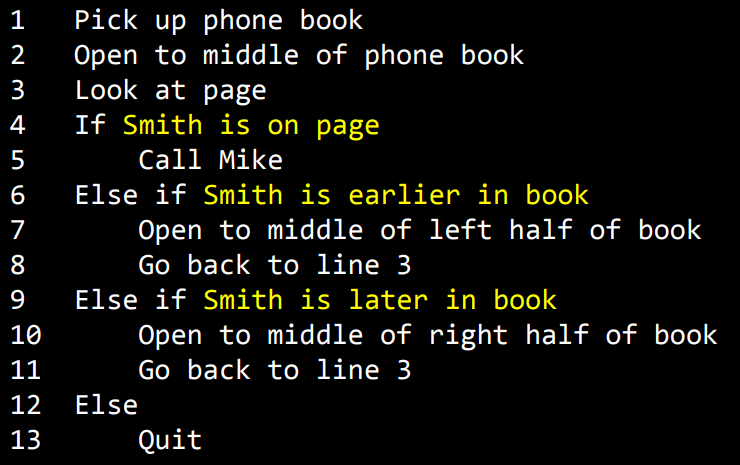
이처럼 노란색으로 표시된 조건의 내용은 불리언 표현(boolean, 참-거짓)이라고 한다.
답이 예 (True, 참) - 아니오 (False, 거짓) 으로 나오는 0 또는 1로 나오는 질문을 뜻한다.
(일반적으로 True는 1을 False는 0을 뜻한다.)
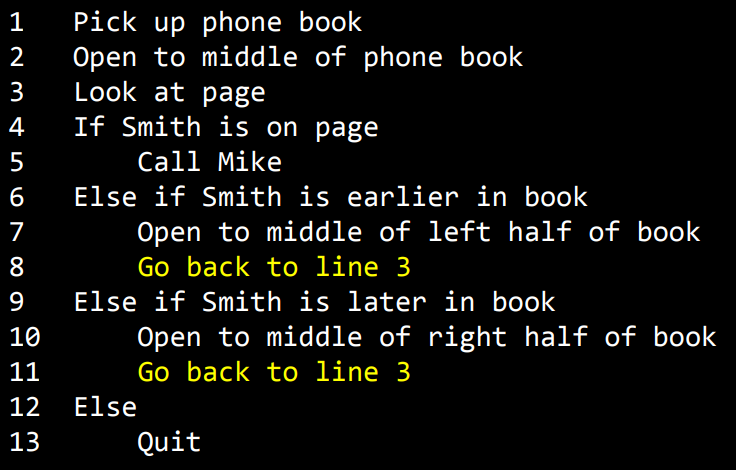
마지막으로 Go back 즉 다시 돌아가서 반복해야하는 것들을 루프(loop)라고 한다.
어떤 일을 계속 반복해야할때 쓴다.
함수,조건,불리언, 루프 외에도 다양한 것들이 있다. (변수variables, 쓰레드threads, 이벤트events) 이것들을 사용해서 다음 강의부터 의사코드방식이 아닌 실제 프로그래밍 언어로 다뤄볼 것이다.
boostcourse에서 제공하는 자료
추가적으로 라면 끓이는 방법을 의사코드(Pseudo code)로 표현해보았다.
준비물 : 라면, 건더기스프, 양념스프, 수도꼭지, 라면냄비, 가스레인지, 젓가락, 계란,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
1. 라면냄비를 집는다
2. 라면냄비에 수도꼭지를 틀어 물을 넣는다.
3. if 짜게 먹는다면 then 500ml를 넣는다.
4. else if 싱겁게 먹는다면 then 600ml를 넣는다
5. else 평범하게 먹는다면 then 550ml를 넣는다.
6. 수도꼭지를 잠근다.
7. 라면냄비를 가스레인지에 올려놓고 and 불을 켠다.
8. while 물이끓지않는다.
9. 기다린다.
10. 라면을 뜯고 양념스프 and 건더기스프를 먼저 넣고 and 면을 넣는다.
11. 뚜겅을 닫는다.
10. while 기다린시간이 1분이 넘지 않았다.
11. 기다린다.
12. 뚜껑을 열고 and 젓가락으로 면을 들었다 놓았다를 반복한다.
13. if 달걀을 먹는다면 then 계란을 깨서 넣는다.
14. if 탁한 국물을 좋아한다면 then 계란을 젓가락으로 풀어버린다.
15. else if 맑은 국물을 좋아한다면 then 계란이 익을때까지 기다린다.
16. 불을 끊다.
17. 라면을 맛잇게 먹는다